
In Anknüpfung und Ergänzung an die Beiträge
– In eigener Sache: ein neuer Kalender?!
und
– Next Generation ng.daybyday.press
hier nun der allfällige "Beitrag für Fortgeschrittene".
Ziel dieses Artikels ist es zu erklären, warum es notwendig ist, nach mehr als einem Jahrzehnt nicht nur eine weitere Version 2.0, 3.0, ff. zu implementieren, sondern den Kalender in seiner bisherigen Erscheinungs-Form durch ein neues Format abzulösen.
Geschieht das nicht, wird der von der DNB eingesetzte "Crawler" nicht nur alle seit dem Ende 2003 veröffentlichten Beiträge zu erfassen, sondern versuchen, alle Seiten zu erfassen, die der JQuery-Kalernder technisch zur Verfügung stellt.
Nochmals im Klartext: der "Crawler" ist ein Programm, das sich auf den bereits veröffentlichten Internetseiten tummelt und alles dort Veröffentlichte so fixiert, dass es auf einer eigenen davon unabhängigen Plattform wieder dargestellt - und damit dokumentiert - werden kann.
Das ’klassische’ Beispiel dafür ist die WayBackMachine-Seite

https://archive.org/, ein Archiv mit einer Rückblick- und Einblick-Möglichkeit in mehr als zehn Milliarden Webseiten. Eine Initiative, die nach wie vor hohe Anerkennung und Unterstützung verdient.
Und die sich bereits um einer Reihe von Einträgen bemüht hat, in denen ebenfalls der Schriftzug "daybyday" erscheint [1] in der aber bislang diese - wie gesagt sei 2004 - fortwährend gefüllte Seite nicht mit erfasst wurde.
Der Grund liegt darin, dass im Gegensatz zu allen anderen bislang erfassten Seiten der bisher verwendete Kalender so beschaffen ist, dass er kein Anfangs- und kein Enddatum bereitstellt. Quod erat demonstrandum: Hier sehen wir, dass dieser Kalender ’unendlich’ weit zurückgehen kann:
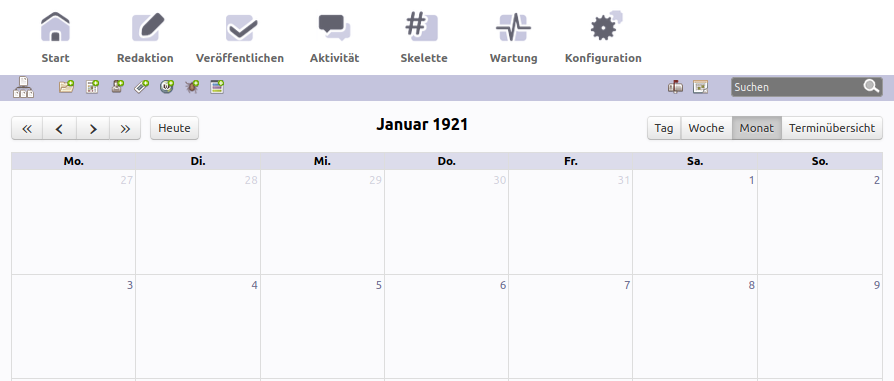
aber auch unendlich weit vorausschauen:

An einem solchen Konstrukt wie dem auf daybyday.press holt sich aber jede Art von "Crawler" eine Abfuhr, da es ihm nicht möglich ist, Start- und aktuellen Endpunkt dieses Kalenders zu erkennen.
Um dieses Problem zu lösen, wurde neuer Code geschrieben, der nunmehr den "Crawlern" nur noch Links zu Kalenderseiten mit real existierenden Artikeln zeigt:
Hier wird der älteste Artikel ermittelt:
<BOUCLE_zumAnfang(ARTICLES){id_rubrique}{par date_redac}{date_redac>0}{0,1}>
<a href="spip.php?page=rubrique&id_rubrique=#ID_RUBRIQUE[&jahr=(#DATE_REDAC|affdate{annee})][&monat=(#DATE_REDAC|affdate{'n'})]" [title="zum ältesten Artikel : (#DATE_REDAC|affdate_mois_annee)"]>||<-- </a></BOUCLE_zumAnfang>Und der Endpunkt in der Zukunft:
<BOUCLE_zumNeuesten(ARTICLES){id_rubrique}{!par date_redac}{date_redac>0}{0,1}>
<a href="spip.php?page=rubrique&id_rubrique=#ID_RUBRIQUE[&jahr=(#DATE_REDAC|affdate{annee})][&monat=(#DATE_REDAC|affdate{'n'})]" [title="zum neuesten Artikel : (#DATE_REDAC|affdate_mois_annee)"]> -->||</a></BOUCLE_zumNeuesten>Erläuterungen zum Code sind hier zu lesen:
SPIP - Managing Dates
Dadurch werden die "Crawler" und "Spider" nicht mehr in die endlosen Zukünfte und Vergangenheiten geschickt, sondern nur mit den endlichen Daten dieser Website konfrontiert.
Damit wurde das wichtigste Hindernis bei der Archivierung beseitigt. Die Nächste Generation von Day by Day ist auch in vollkommen neuem HTML 5 geschrieben und alle Code-Altlasten aus bald 20 jahren Entwicklung entsorgt.